

今回はAWSのglueというサービスの一つでjobを利用していきます。
jobで実行するのは今まで作成していたデータ加工のpythonファイルを利用してます。
Table of Contents
glueとは
glueとは簡単に言えばデータの抽出、変換、読み込み等を簡単に行えるようなサービスです。
jobを作成してみる
jobを実行するにはクローラを先に実行して、データカタログに登録しておかないといけません。
すでにクローラを作成して実行しているところから始めます。
まずはjobを作成します。
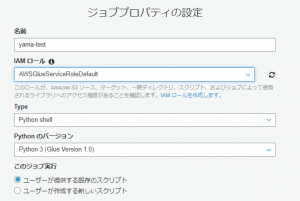
名前:好きな名前
IAMロール:クローラで利用したのと同様のもの
type:今回は自分で作成したpythonを使うのでpython shell
プログラムをS3に入れて、S3の場所を指定します。
と順々に進めていきます。
今回のプログラムで接続は関係ないので、そのままスクリプトの編集へ
スクリプトを確認して、問題なければ保存をします。
実行したかったら保存して実行。
スケジュール設定
ここからが本番。
作成したjobを定期的に呼び出したいときにはトリガーを作成します。
これです。

トリガーの追加
ではトリガーの追加を行っていきます。
今回はカスタムで頻度を設定したいと思います。
カスタムで頻度を指定する際はCron式を使うそうです。
今回の設定では毎日8時と18時にjobを動くように設定します。なので、Cron式で書くとこんな感じ。
0 3,23 * * ? *
| 分 | 時 | 日 | 月 | 曜日 | 年 |
|---|---|---|---|---|---|
| 0 | 3,23 | * | * | * | ? |
| 0分に | 3時と23時に | 毎日 | 毎月 | 毎曜日 | 毎年 |
ここで正規表現も出てくる。
さて、Cronの設定が完了すると次へ
今回はyama-testというjobに先ほど作成したトリガーを設定したいと思います。
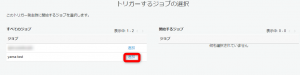
そのため、yama-testというjobを追加。そして、次へ。
確認があるので問題が無ければ完了とします。
作成時にトリガーを有効にするのもお忘れなく!
まとめ
今回はcron式を使ってjobのスケジュール設定を行ってみました。
cronの設定を見ることはあったけど、自分で設定することが今までなかったので良かったです。
また、時差の計算とか面倒だなあと思いました。
日本の時間に合わせたいのに…ということで僕は今回こちらのサイトを利用しながら計算したので参考にもしてください。
参考
Glueについて
19.クローラの必要性

